Go back
Using AI for document comparison
Document comparisons are just one of the many immensely powerful use cases that you can to with Retrieval Augmented Generation! With just a few steps, you can easily process and compare documents that you have.
Leonard Püttmann
1/8/2024

Join us as we explore an intriguing application of Language Learning Models (LLMs) in the insurance industry. Beyond their well-known role in powering chatbots, LLMs like ChatGPT excel in tasks such as document understanding.
Check out our full range of LLM applications here → https://www.kern.ai/catalogue
Where previously projects to create policy Synopsis projects took weeks, they can now be done within hours! Let’s delve into the details of this efficiency revolution.
Making our data ready for AI
To showcase this Synopsis project to you, we have created some realistic dummy datasets for a fictitious company called Global Guard. Global Guard's main products are travel and health insurance (for traveling).
Horizontal versus vertical document comparison
There are multiple scenarios in which a Synopsis makes sense. Sometimes, you have a product and would like to compare it to other products, maybe even to a similar product of a different company. This is super important because it allows you to understand your positioning much better and act accordingly, especially when you know what aspects of your products your customers value the most. We can call this a vertical comparison.
In another case, you might simply want to compare different versions of the same policy or document, perhaps from different years. If there is a different document for every year of the last decades, this can be a huge challenge, as the devil’s in the details. All these documents are very similar, with just some minor nuances changing here and there. In this case, our LLM-based approach can also be very helpful, as LLMs can help us find the right passages and work through large amounts of text very quickly and accurately.
Asking the right questions
When creating a Synopsis, the hardest part it to ask the right questions of where these policies might differ. But, in most cases, those questions are already defined in companies with many different policies and the remaining part is to find an answer to these questions.
These questions are super company-specific and depend on the products and services a company offers.
In reality, we often want to compare multiple dozen or even more policies at the same time, but to keep things more clear here, we are only going to compare two documents for now, which is hard enough as it is.
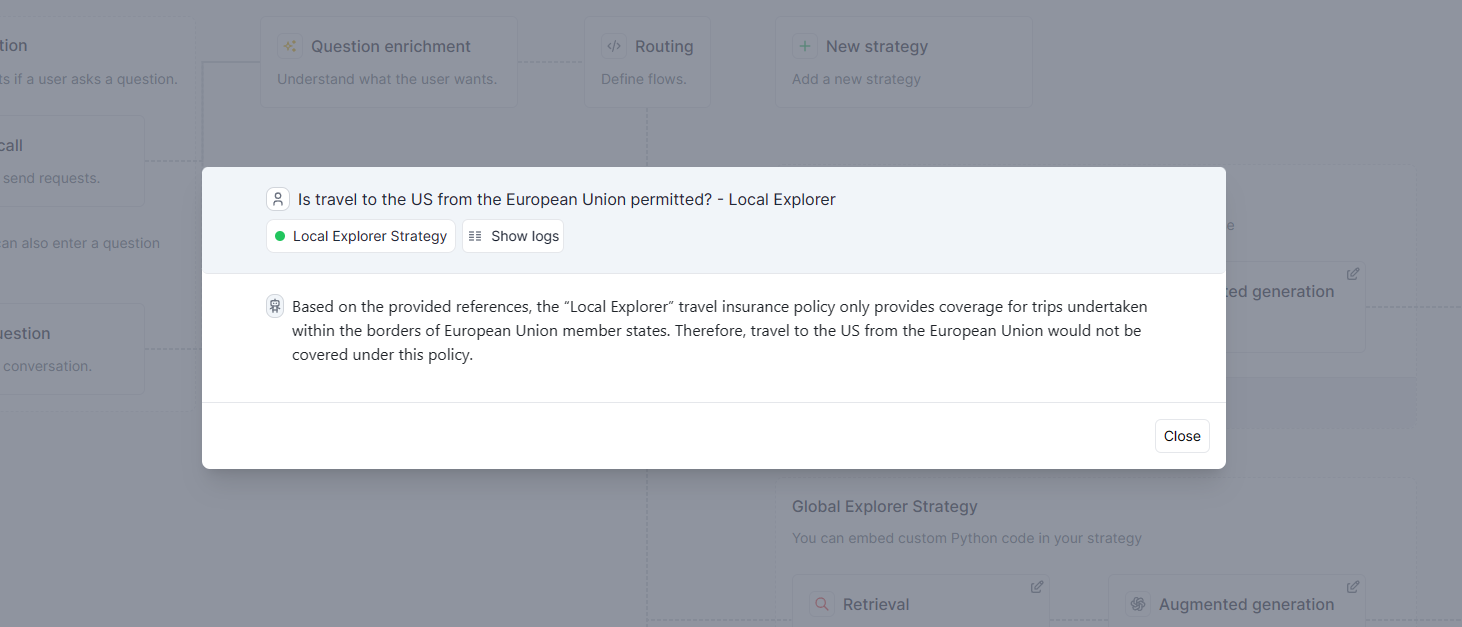
For our case, we are going to ask six questions to our insurance policies:
- Is travel to the US from the European Union permitted?
- What Leisure and Sports activities are covered?
- What is the amount of coverage for flight delays?
- What is the definition of a trip accident?
- Which types of diseases are covered to be eligible to trip cancellations?
These questions are not trivial at all. The Global Explorer and the Local Explorer are insurance for different kinds of trips. While the Global Explorer is an insurance for worldwide trips, so it would also a trip to the jungle, where people could be attacked by giant snakes or huge spiders. The Local Explorer, on the other hand, is meant for trips within Europe. As there aren’t that many snakes around in Europe, incidents involving these are not covered by the policy.
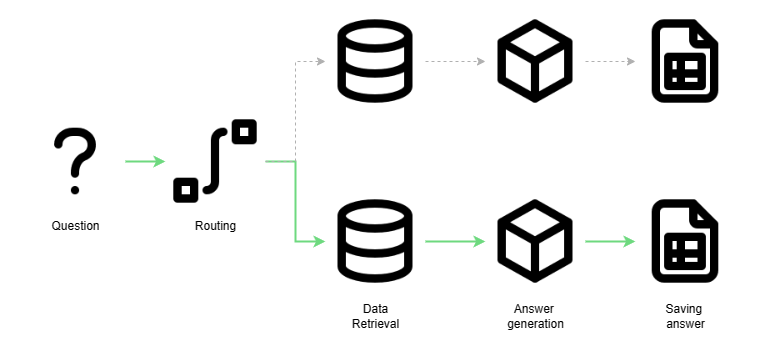
To answer all these questions for each document, we pass the question as well as the name of the document to our system. In the picture below, you can see all the steps in our pipeline. One of these steps is the routing, which detects which document we are interested in. That is especially important for the next step, the retrieval.
The retrieval works like a mini search engine for our data. When we ask a question about the Global Guard policy, this search engine can dynamically find only results for this document here. To make this more tangible, we have created two separate strategies for each document here, but the great thing is that you can super easily implement and use these filters, even with dozens or hundreds of different documents!
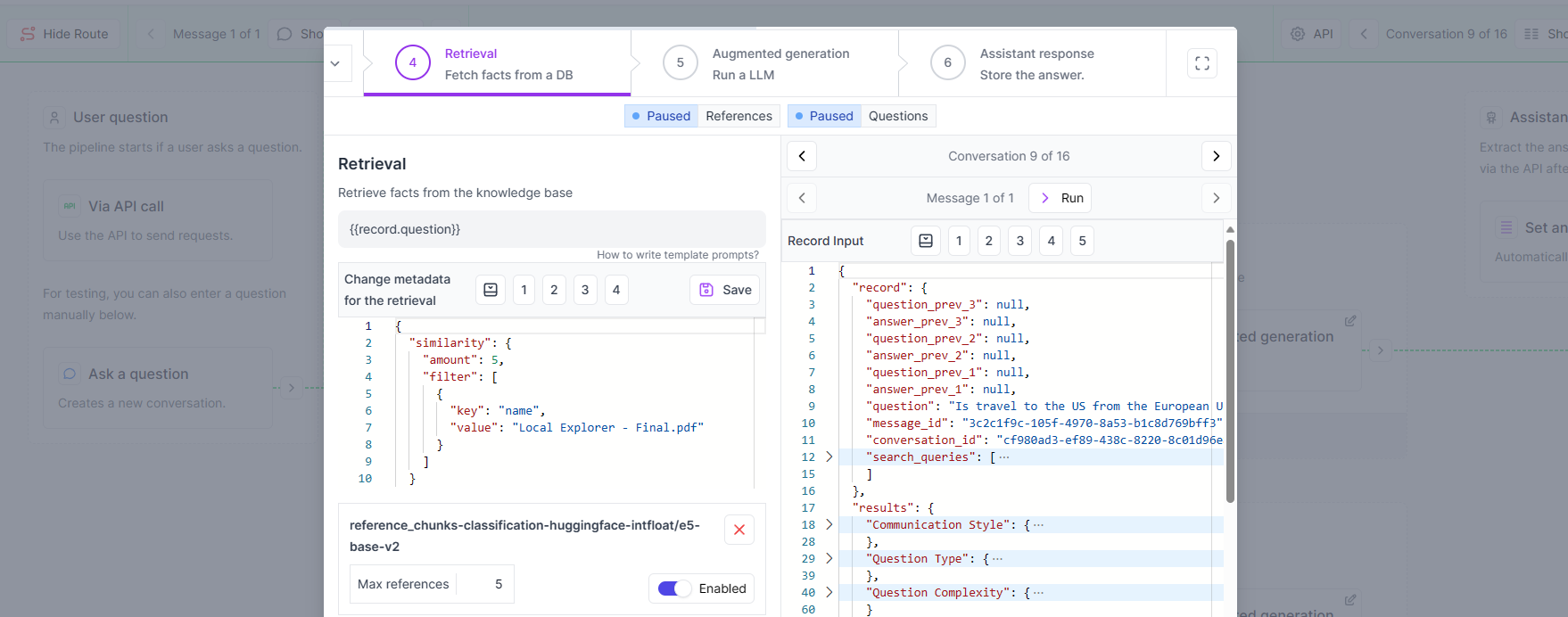
Filtering for the right documents
The question now is: How can we answer all these questions without manually searching in the documents, and also without even specifying the name of the document? That’s the point where Meta filters come into play. Yes, that might sound scary, but it’s actually quite easy. Let’s have a look!
Our data is stored in a so-called Vector Database. The name Vector Database isn’t all that fitting, as they are really more like a Vector Search Engine, because that’s what they basically are: A mini search engine for your own data! In a nutshell, we use LLMs to process our data and then store the result in this Vector Database. When we ask a question, like “What is the definition of a trip delay?”, we can retrieve the top n most similar pieces of information from our data, in this case, our insurance policies.
Implementing GPT
In the last step, we are going to use GPT to answer all the questions that we have prepared for our Synopsis use case. Adding an LLM to our pipeline is super easy, and we have the option to choose different LLMs. At the moment, we have the option of choosing models from vendors like:
- OpenAI
- Mircosoft Azure
- Open-source models like LLaMA 2
When data privacy is important, we would recommend using a model that is hosted by Microsoft Azure directly. Alternatively, it is becoming more and more viable to use a model like LLaMA 2 as well! In our case, we will be using a GPT model directly from OpenAI, but know that there is a lot of flexibility when it comes to choosing the LLM!

In the LLM node above, we can write down some instructions for our model and also check the data that is injected into the prompt of the model. Additionally, we can choose the LLM provider and set parameters for the model to control its behaviour even further!
After that, we are ready to test out the pipeline!
Filling out our Synopsis
Now that we have set everything up, it is finally time to feed all the questions through the pipeline. The result is an Excel-like spreadsheet with all the documents and answers, organized column-wise:

As Excel allows us to do API calls, we could quite easily automate all of this, either with classical VBA scripts or even the new Python integration. That means that we can super easily add new questions or new documents, run our pipeline, and have the answer within just a few minutes!
Final remarks
Document comparisons are just one of the many immensely powerful use cases that you can to with Retrieval Augmented Generation! With just a few steps, you can easily process and compare documents that you have, while also making sure that all the data is saved and that you are not tied to any one provider for LLMs!
Sign up for our newsletter to get the latest updates on LLM.
Go to newsletterSee it in action.
Related use cases.
Learn more about this in our use cases.